爬虫的原理:首先收集一些种子页面,然后跟踪这些页面的链接来收集新的链接,如此循环。
爬虫用途:
- 搜索引擎索引(如googlebot)
- 网络档案(如图书馆档案)
- 网络挖掘(如金融公司爬虫获取股东会议和年度报告等)
- 网络监控(版权,商标侵权,盗版发现)
第一步 提问明确需求
本例中需求:
- 用于搜索引擎索引
- 每月1billion的页面
- 只考虑HTML
- 需考虑网页新增和更新
- HTML最长存储5年
- 需要忽略重复内容
可以考虑的特性:
- 可扩展性(Scalability:易于扩展规模)
- 稳健性(处理特殊case)
- 礼貌性(不能短时间向同一网站发送太多请求)
- 可扩展性(Extensibility:易于增加新功能)
估值:
- 假设每月下载1billion页面
- QPS:400/s
- Peak QPS: 400*2 = 800/2
- 假设每个页面大小500k
- 1billion * 500k = 500T每月
- 5年存储:500T * 12 * 5 = 30PB
第二步 high-level设计
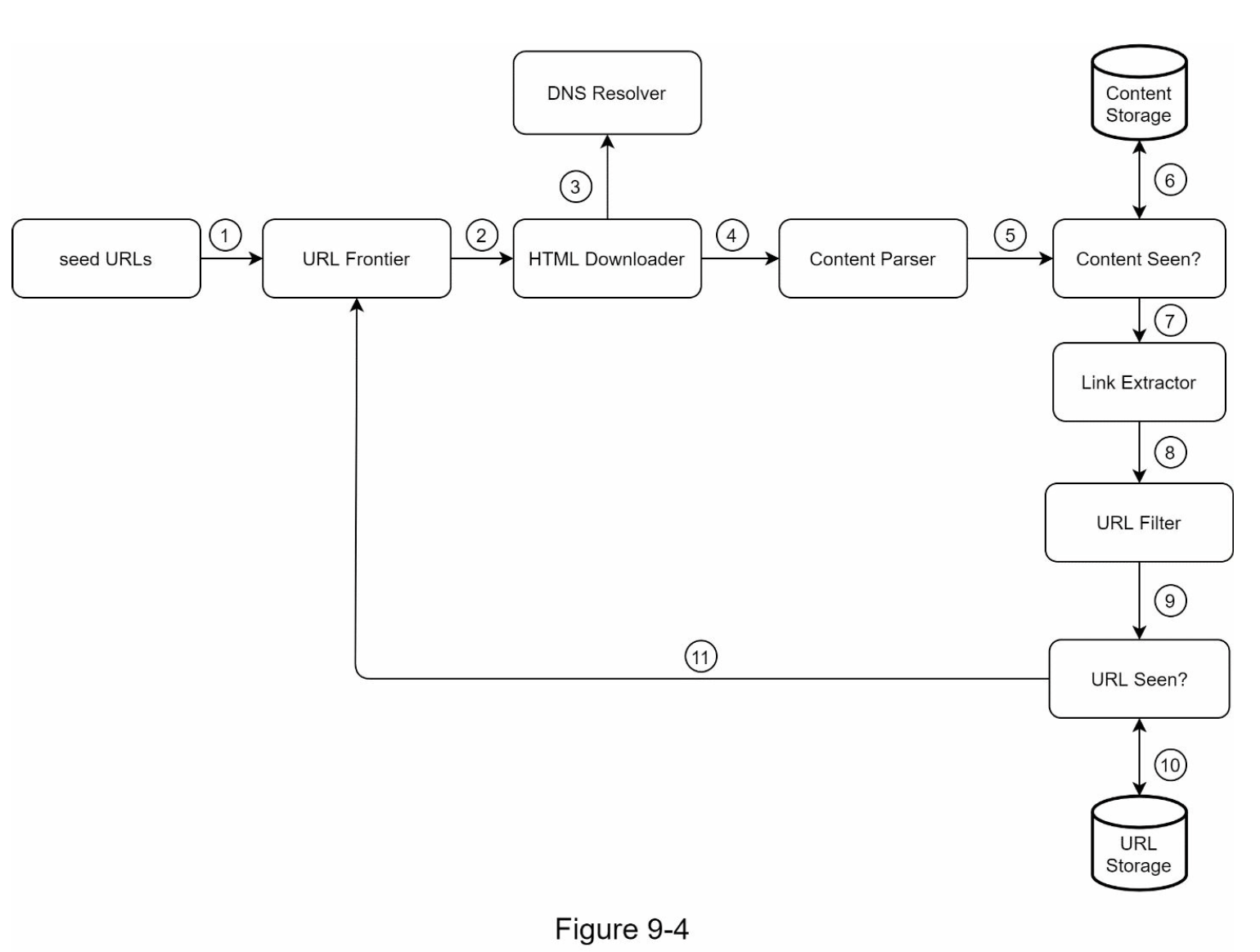
第三步 深入讨论
- 算法:DFS vs BFS
- DFS深度太深,一般不适用于爬虫。
- 使用BFS考虑以下两个问题:
- 大量请求同时爬同一个网站,不友好
- 需要考虑不同网站优先级
- URL frontier
- 添加两组队列:
- 优先级管理:对URL进行优先级排序,并放入不同优先级的队列中
- Politeness管理:将特定host映射到同一个队列,并在worker维持一个delay
- 保持内容最新:全部重新爬虫费时费资源,可考虑一些策略来更新部分网站内容
- 存储:磁盘和内容混合存储,添加缓冲区等
- 添加两组队列:
- HTML下载器
- Robots Exclusion Protocol
- 性能优化
- 分布式
- 缓存DNS解析结果
- 考虑地理位置优化
- 设置超时时间
- 保持稳健性
- 通过一致性哈希扩展下载服务器
- 保存爬虫状态和数据,可在故障后重启
- 异常处理
- 数据验证
- 功能扩展
- 增加图片下载
- 增加监控模块
- …
- 问题内容检测
- 校验冗余
- Spider traps检验
- 噪音排除
第四步 总结
其它可讨论的点:
- 为支持动态生成的链接,在解析页面前可进行服务端渲染
- 垃圾过滤
- 水平扩展
- 可用性、一致性和可靠性
- 添加分析器